Deep Deterministic Policy Gradient (DDPG) with and without Ornstein–Uhlenbeck process

Replacing the Ornstein-Uhlenbeck Process Action Noise by simpler Normal Action Noise or Adaptive Parameter Noise
Motivation
In my Deep Reinforcement Learning course at Udacity, I had to do a project solving the Reacher Environment. You can choose between different algorithms to implement and I chose DDGP. In the original paper, the researchers introduced the Ornstein-Uhlenbeck process for generating random values to be applied as action noise. They write:
As detailed in the supplementary materials we used an Ornstein-Uhlenbeck process (Uhlenbeck & Ornstein, 1930) to generate temporally correlated exploration for exploration efficiency in physical control problems with inertia (similar use of auto- correlated noise was introduced in (Wawrzyn ́ski, 2015))
This sounds more like intuition than a strong connected reason but of course, it is worth giving it a try. And in the end, it works. But this alone does not explain, why this complicated algorithm to generate a series of random numbers instead of using common normal distributed random numbers will improve the learning.
So I decided to try out using common normal noise and adaptive parameter noise as well.
The Environment
Before I discuss the different methods, I give some introduction about the used environment. The environment is described on the project page as follows:
In this environment, a double-jointed arm can move to target locations. A reward of +0.1 is provided for each step that the agent’s hand is in the goal location. Thus, the goal of your agent is to maintain its position at the target location for as many time steps as possible.
The observation space consists of 33 variables corresponding to position, rotation, velocity, and angular velocities of the arm. Each action is a vector with four numbers, corresponding to torque applicable to two joints. Every entry in the action vector should be a number between -1 and 1.
The environment is considered solved, when the average (over 100 episodes) of the average scores is at least +30.
I used a version with 20 identical agents, each with its copy of the environment. More details like where to download and how to install you will find in the GitHub repository of my implementation.
Implementations
I will only explain the parts that differ and show only the relevant parts of the code. You find the complete implementations in the GitHub repository and for the math, please have a look at the linked papers.
As part of the original DDPG concept, the state values will be forward passed thru the Actor and we get the action values. While training noise will be added to the action values and they will be forward passed thru the Critic together with the state values. For the noise, they used the Ornstein-Uhlenbeck process. So the noise is called ou-noise for short.
Ornstein-Uhlenbeck Process Action Noise
Ornstein-Uhlenbeck Process
The Ornstein-Uhlenbeck Process is a stochastic process discovered and published in 1930 by G. E. Uhlenbeck and L. S. Ornstein in their paper “On the Theory of the Brownian Motion”. It has applications in physics and financial mathematics.
The process has some interesting properties. It is a Gaussian and a Markov process. I assume, that’s where the intuition to use it as action noise came from. The simplified key properties we need to know for our application are:
- The next value depends on the current value.
- The generated values have a normal distribution.
An implementation of the process looks as follows:
Adding OU-Noise to the Action Values
The class must be initialized once with the needed action size.
Then every call of the sample()-method will give the next values (ou-noise) used for adding noise to the action.
In addition, all implementations I saw, reset the ou-noise after each episode. I also didn’t find a reason for this. But I haven’t tested, if it works without too.
Result
After some tests and hyperparameter tuning I got the following results:
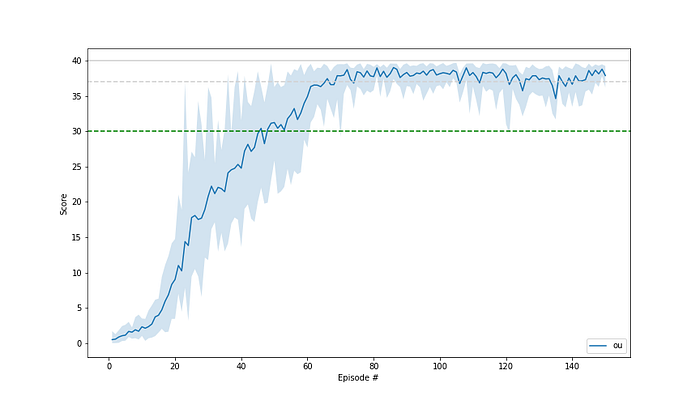
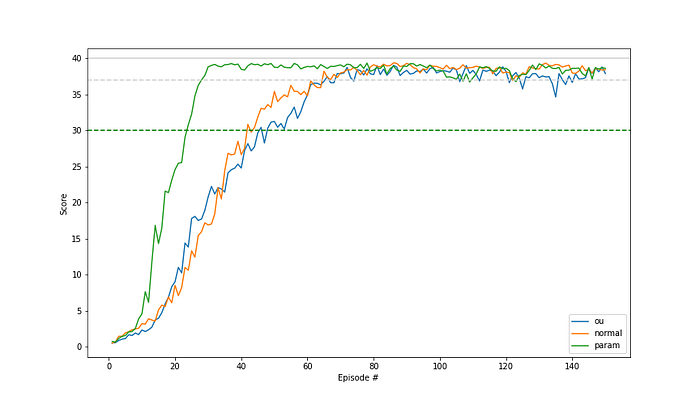
I think those are good results. The learning progress is relatively even. The average score is reached for the first time after 46 episodes and it then stays above this value. And it reaches consistently high values.
Normal Action Noise
After I got it running and the agent learned well, I kept everything the same and only replaced the ou-noise with normal noise. Therefore the ou-noise class for generating the values is no longer necessary and can be removed.
And I changed the line that adds the noise:
Here we get a new hyperparameter, normal_scalar that scales how much noise is added. The line adds random noise to the action that has a standard normal distribution, a mean of 0, and a standard deviation of normal_scalar.
Result
With the normal_scalar set to 0.25 I got:
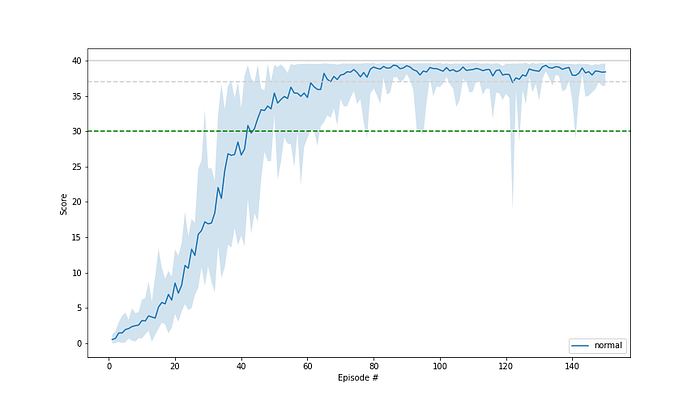
The result looks similar to that from the ou-noise. The learning progress is relatively even. The average score is reached for the first time after 43 episodes and it then stays above this value. And it reaches consistently high values too.
Adaptive Parameter Noise
The Adaptiv Parameter Noise is a little more complex but interesting.
The Idea: Adding noise to the weights of the Actor, forward pass the state values and get noised action values this way instead of adding the noise to the action values.
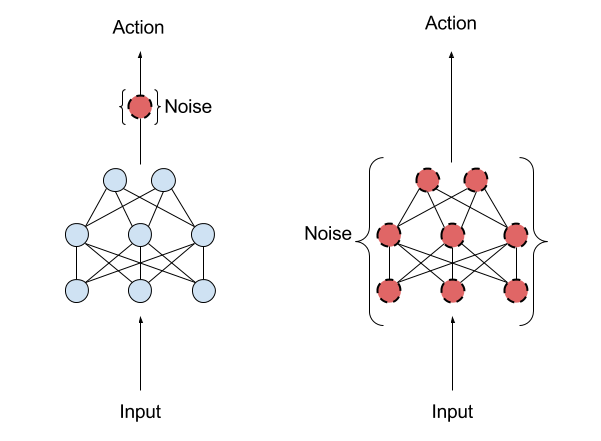
Adaptive
In the previous methods, we can simply adjust the amount of action noise.
If we put the noise directly to the weights of the network, we can not say how much it will affect the action values. And even worse, the impact will change over time. And that’s, where adaption comes into play.
We make a copy of the current Actor and put a little amount of noise to its weights. Then we forward pass the state thru both networks and calculate the distance between the results.
If the distance is greater than the desired value, we decrease the amount of noise we put to the weights next time, and if the distance is lower than the desired value, we increase the amount of noise. The desired value is a new hyperparameter we chose similar to selecting the standard deviation on normal noise.
The add_parameter_noise() method of the Actor-network:
Result
After some experiments, I ended up with the desired value for the distance of 0.7 and got the following results. The average score is reached for the first time after 24 episodes and it then stays above this value.
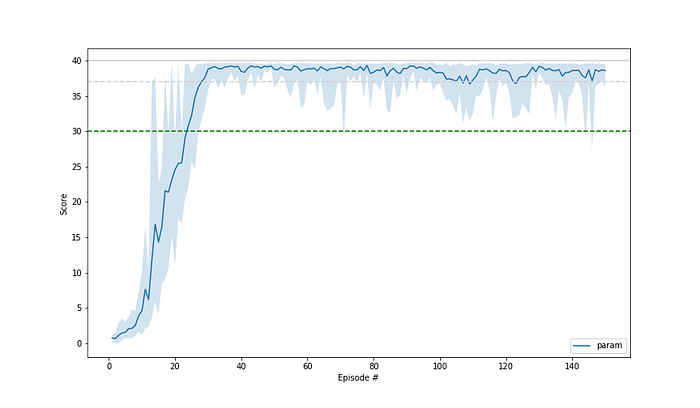
To be honest, I was totally surprised and excited. It learned so fast and stayed so stable.
Comparison and Conclusion
The direct comparison of the results shows impressively the differences. The ou-noise and the normal-noise are producing similar and good results. Their learning curves are looking like expected, and they are fast. But in comparison, the learning curve of the adaptive parameter noise is outstanding and shows an impressive learning behavior.
Closing thoughts and notes
Please be aware, that this is not a scientific work and no proof for anything. These are only some experiments. Maybe that there are cases and well-tuned hyperparameters where ou-noise gives better results than the others.
Nevertheless, it shows that simple normal noise gives similar results too.
During my research for this article, I found a page from Open AI about DDPG and they write:
The authors of the original DDPG paper recommended time-correlated OU noise, but more recent results suggest that uncorrelated, mean-zero Gaussian noise works perfectly well. Since the latter is simpler, it is preferred.
I think Deep Reinforcement Learning is not the easiest subject to learn. ou-noise does not make it easier, especially when it is unnecessary. Okay, on the other hand, I learned a lot.
I want to use the article to encourage other students to try the other methods, especially adaptive parameter noise.
